
Eighth Thing: Sensitive Data
Do you have concerns regarding the management of sensitive data? Are you unsure how to comply with mandates imposed by various regulations? Have you considered if your data about research participants are adequately protected following the recent national data breaches? Do you know if the systems you are using are aligned with recommended cybersecurity standards?
This article by Kimberley D’Costa will by help address some of these questions, and an interview with Adrian Bickerstaffe will give you an insight into how researchers manage working with sensitive data every day.
Working safely with sensitive research data
Responsible research data management is a critical component of research. It enables you to safely store and analyse data, ensure the privacy of research participants, collaborate with others, and support your research findings when you publish them. An increasing number of projects across research disciplines involve sensitive data in diverse formats. This might include research using identifiable personal or health information about individuals, research with national security implications, or research using socially or politically sensitive information.
Sensitive research data can cause significant harm if disclosed to or accessed by unintended parties, and therefore warrants particular attention. But as regulatory mandates, cybersecurity guidelines, research methods, and technology are always changing, it can be a challenge to understand research requirements and then implement adequate as well as effective controls to safely manage your sensitive research data. While the risks resulting from the mismanagement of sensitive research data can never be eliminated, engaging with a combination of secure infrastructure, supporting guidance, training, and advisory services provided by the University of Melbourne can help you minimise these concerns. Some of the key tools and resources available to enable sensitive data management are described below.
Resources to help you work smarter, not harder
The Research Data Management Policy
The University’s updated Research Data Management Policy (MPF1242) outlines what you need to consider at different stages of your research and can help clarify who is responsible for different aspects of data management. It also aligns with current principles in data protection and open research.
The Research Data Classification Framework
The Research Data Classification Framework presents regulatory requirements and best-practice cybersecurity standards in a simple and actionable format. It is designed to help all researchers, including professional research staff and graduate research students, assess the sensitivity of your research data and make informed decisions about data collection, storage, analysis, and retention, thereby meeting your research responsibilities.
The Framework includes:
- Four data classification levels that categorise data based on the potential severity of harm to research participants, researchers, or the University due to access by unauthorised parties
- A simple and easy to use Research Data Classification Tool to help classify your data into one of the above classification levels
- Research Data Handling Guidelines, advice on recommended University systems and resources, and additional support available to help manage and safeguard sensitive data.
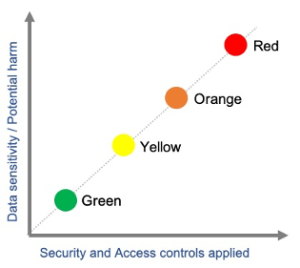
Image: With increasing data sensitivity, the Research Data Classification Framework recommends more rigorous security and access controls. Data assessed as ‘Red’ per the Framework will require the most controls to be applied and data assessed as ‘Green’ will require the least. The representative graph has been sourced from the Research Data Classification Tool.
The recommendations in this Framework will be updated over time, ensuring you will always have clear, accurate, and timely guidance on the appropriate management of sensitive research data. This means you can feel confident that using the Framework will help align your research with best practice standards, build trust with research participants and data providers, and overcome barriers to working with sensitive research data.
The Secure Research Environment (SRE)
A critical component of sensitive data management is ensuring that research data is safeguarded over the entire research lifecycle i.e., from data collection to research outputs. The University has a range of tools and systems suitable for the storage and management of different classifications of data.
The new Secure Research Environment (SRE) is purpose-built for the processing, analysis, and storage of highly sensitive research data (i.e., data classified up to ‘Red’ by the Research Data Classification Framework). The SRE is a highly protected, isolated virtual desktop infrastructure (VDI)-based solution with on premises storage and scalable computational resources.
The SRE provides researchers with secure and governed access to sensitive data and associated software and tools, along with in-house support to help you use it. Data in the SRE never leaves the UoM network and transfer of data out of the system is mediated through an approval process with a nominated data custodian. This process ensures only non-sensitive outputs are removed. Importantly, the SRE is ISO27001-certified, which is the industry gold standard for certification of information security management systems.
Want to learn more?
For further information on managing your research data, refer to the Research Data Management website. The interactive Research Data Services Directory also provides a comprehensive catalogue of research tools, support, advice, or specialist data collaborators available.
Managing Data @Melbourne is the University’s research data management training program. It consists of six short modules which outline the fundamental practices of good data management, including how to write a data management plan. A complimentary resource is the File Management 101 webinar via Researcher@Library video library.
Submit a form via ServiceNow with questions or enquiries related to your research data management. For questions or information on getting started with the Secure Research Environment, contact the SRE team at secure-vm@unimelb.edu.au. You may also contact the University’s Research Data Management Program team at rdm-program@unimelb.edu.au.
About the author
Dr Kimberley D’Costa is a Project Officer for the University’s Research Data Management Program. As part of the Petascale Campus Initiative since 2019, the Program has engaged in several projects to uplift the tools, resources, and support available for researchers to manage their research data in a rapidly evolving regulatory and technological environment.
Interview with Associate Professor Adrian Bickerstaffe
What is your role and research focus?
I’m the Head of Research Computing in the Melbourne School of Population and Global Health (MSPGH). I lead a population health informatics team that operates from the Centre of Epidemiology and Biostatistics and is embedded directly within the research environment. We support a wide range of health research domains, developing technological solutions that enable, optimise, and translate population health research.
Our work provides the technological foundations for research towards reducing the burden of breast and colorectal cancer and lung disease, improving health outcomes for indigenous communities, advancing sexual healthcare pathways, and leveraging twin study designs, among other domains. We translate research findings to public benefit, for example, through the development of online risk estimation and decision support tools. We also provide knowledge and expertise to bridge the gap between the University’s central technology teams, whose perspective is highly computing-oriented, and population health researchers who are focused on medical research questions and typically do not have a technical background.
How have you used/interacted with the topic of sensitive data?
Working with sensitive data is a daily part of supporting population and global health research. The studies inherently involve information about the lives and health of individuals, and the people close to them. Maintaining the privacy and security of study participant data is paramount, and subject to University policy, and State and Federal government legislation. Each new study raises questions about appropriate data storage and analysis platforms, access control, and data retention/disposal. For each study, we work with researchers to understand the traits of its datasets. We analyse the data sources and their locations, data acquisition methods, raw data types and their magnitude, and the research methods, including planned analyses. From this review process, we propose a data management plan that incorporates data management practices and platforms that are appropriate for the sensitivity of the data, compliant with policy and legislation, and feasible with respect to study practicalities.
How has this topic helped you work smarter, not harder when managing your research?
Understanding sensitive data and proactively planning how to manage it saves substantial time over the course of a research project, particularly since population health studies often run for months, years, or even decades. Choosing the right platforms for your data not only ensures participant privacy but can also streamline data management processes and avoid costly mistakes that divert valuable research time and may cause reputational damage.
The University provides resources on managing sensitive data that are a major asset to my Informatics Team and MSPGH researchers. We regularly receive enquiries from research groups who are seeking advice and guidance on research data management. Being in the population health domain, we know that the data are likely to be sensitive. We can now point researchers to the Research Data Management section of the Research Gateway and advise them to apply the Research Data Classification Framework. The Framework is written in language suitable for researchers of a non-technical background. It empowers researchers to understand the sensitivity of their data in a self-directed way, and importantly, helps them locate appropriate University platforms to store and analyse their data. The Framework has credibility as an official University resource, giving researchers confidence they are managing data in a compliant way.
The Research Data Classification Framework saves my team time by being an up-to-date, centrally available, and officially endorsed resource that answers many questions formerly directed to us. Naturally, the Framework is also a boon for my Team, helping us formulate data management plans and technical solutions more rapidly. Moreover, the resources help us stay abreast of changes to data handling guidelines and new data platforms.
What is your number one (top) tip for graduate researchers regarding sensitive data?
Use the Research Data Classification Framework to your advantage and apply the Research Data Classification Tool as early as possible. Doing this will help you gain a better understanding of the sensitivity of your data, and greatly assist in directing you to appropriate University storage and analysis platforms. It will place you in good stead from the outset of your project and pay tangible dividends over the course of your studies.
Find out more about Associate Professor Adrian Bickerstaffe’s research here.
Cite this Thing
You are free to use and reuse the content on this post with attribution to the authors. The citation for this Thing is:
D’costa, Kimberley; BICKERSTAFFE, ADRIAN (2024). Eighth Thing: Sensitive Data. The University of Melbourne. Online resource. https://doi.org/10.26188/25287511
Featured image credit: Illustration by Akitada31 on Pixabay.
Categories
Leave a Reply