Hexed – discoveries and challenges in archiving born-digital records
Lachlan Glanville, Assistant Archivist, Germaine Greer Archive

Removable media such as floppy disks from the early days of PC ownership are now degrading rapidly and becoming increasingly difficult to access. Without swift action, years of unique records could easily become irrecoverable. Archivists at UMA have been collaborating with colleagues across the University such as Research Platforms, Digital Scholarship and the ESRC on a pilot project on how to extract and preserve digital records. The Greer Archive removable media is one case study.
When the Germaine Greer Archive was transferred to the University of Melbourne Archives in 2014, alongside the paper files, manuscripts and other “traditional” materials, we received over 500 items of digital removable media including floppy disks, CD-Rs and USB sticks dating from 1985 to the present. The files contained in this part of the archive cover all facets of Greer’s career, including her emails, journalism copy, drafts of books (including the unpublished Fortune’s Maggot on Margaret Thatcher), transcriptions of archival sources of women poets and lecture resources. While some of these documents are duplicated in the paper record, a substantial portion exist only as electronic files. Although contemporary record keeping is increasingly digital, many collecting institutions are only now coming to grips with how we continue the work we’ve done with paper records in the digital realm.
Before we can even think about accessing the files, we need to move the contents off the original media. Our first step is to create perfect copies of the contents of each of these media, a process often referred to as forensic imaging. This encapsulates the disk’s content as a single file independent of the media it’s stored on and preserving valuable contextual data such as file modified dates. These disk images can then be extracted and explored using forensics software. We were able to access most of the formats in the collection with modern drives but the 5.25” floppy disks proved a challenge. While you can still purchase USB connected 3.5” floppy drives, 5.25” drives are no longer made and the old ones cannot be used easily with contemporary computers. Fortunately, active and enthusiastic forums and subcultures have sprung up around refurbishing, extracting and emulating early software and systems.

Enter the Kryoflux. Maintained by Peter Neish for Digital Scholarship’s Data Forensics Lab, the Kryoflux is a piece of hardware designed to interface between old floppy drives and modern computers. It can read magnetic data from floppy disks and then interpret it into a disk image that can be accessed and extracted with forensic software. The problem is, while the Kryoflux can read and record the raw magnetic data on the disks, you need to know the system that created them to translate them into something accessible. After some homework and a lot of trial and error, we were able to create some disk images that contained intelligible data. When we dug into the contents however, the structure seemed off. There were a bunch of file names with the extension .DOC, as you might expect from a writer like Greer. But for each of these files there was also an identically named file with the extension .001. Word, Libreoffice and Notepad could not make any sense of the .doc files, however the .001 files seemed to contain intelligible text interspersed with garbled characters and formatting.

My initial concern was that the Kryoflux software was segmenting files when it translated the magnetic data from the floppies into 0s and 1s. We needed to work out what program had been used to create these files. Fortunately, we had a clue in the caption of one of the disks. Fortune’s Maggot. 3.09.87. Software = Wordcraft. Searching through Greer’s housekeeping files we found brochures for Wordcraft, an early word processing program for the IBM XT150. As ever in the realm of digital archiving, we took this clue to Google. While many early word processing programs such as Word for DOS and Wordstar are relatively well documented (some of which have even been collected and emulated by the Internet Archive), Wordcraft remained fairly mysterious.
Luckily, Wordcraft International still exists as a company, so I sent them an email asking whether any remaining staff had knowledge of the software. My email was passed onto two of the original developers who were somewhat surprised to receive an enquiry about software produced 30 years ago. They explained that the .001 files are individual chapters of a document containing the text and formatting characters, and the .doc files are the index. Further digging produced a scanned pdf of the user manual from 1986. Now we could be fairly confident that the actual content of the files was intact, we still had the problem of garbled characters and formatting.
To try and understand the structure of the documents I opened them up in a “hex editor”. Not witchcraft, but a very useful tool for archivists trying to understand how a file might work without access to the original software that created it. Most people know that digital data is made up of a series of 1s and 0s, otherwise known as bits. A short string of these bits is a byte. A hex editor represents these bytes as a series of hexadecimal pairs, two characters of either 0-9 or a-f. In ASCII (American Standard Code for Information Interchange) most of these values then relate to a single printable character. In this way, the binary string 1001101 is the same as the hexadecimal pair 4d, which in ASCII is represented as an uppercase M. Some bytes relate to non-printable characters, for example, 0d signifies a carriage return. Early word processors took these non-printable characters and used them to apply formatting to the printed document.
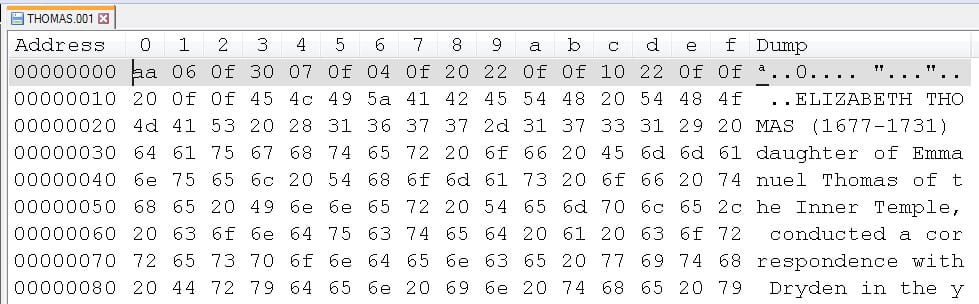
The difficulty here is there was very little consistancy in how these were applied between different word processors. Wordstar used the hex value 02 to toggle bold text, where in Wordcraft it centred the text. Fortunately, the scanned manual found online tells us which hex values relate to formatting changes.
Now we should have almost all the information we need to migrate these documents to a format that will display similar to how they would have been printed. The question is, what format and how do we carry out the migration? An obvious solution would be to use a contemporary word processor like Microsoft Word to replace the non-printing characters with the desired formatting. However, National Library of New Zealand have done interesting work converting legacy Wordstar documents to HTML by replacing formatting characters with mark-up. HTML is well suited for ongoing preservation as an open, well documented language and the syntax in many ways mirrors the way formatting is applied in Wordcraft documents. Perhaps at a later stage we will be able to fund the creation of a script to carry out the conversion and finally make these records available to researchers.
For all the challenges and pitfalls, this is really exciting work. Coming to grips with the issues in this collection has forced us to develop new skills and processes that will help us to carry our work as archivists into the digital future. These skills can then be applied to preserving other valuable records such as the University’s own permanent records and the socially significant community records being formed right now.
Our key challenge at the moment is resources. UMA has various options for digital storage, but none which are informed by international standards and suited to long term preservation of unique electronic records. What we need now is the digital equivalent of the climate controlled storage facility for our physical collections. Without a best practice digital repository, these amazing resources are still extremely vulnerable.
Lachlan Glanville is Assistant Archivist, Germaine Greer Archive at University of Melbourne Archives. He has worked at the National Library of Australia in Pictures and Manuscripts and as assistant archivist at RMIT University.
I like the idea of using a script or manual means to translate the Wordcraft/Wordstar documents to html, stroke of genius since it produces a relatively static record. We (Texas State Archives) migrate to PDF for productivity software records to prevent change by other parties that download or request a DIP. I would be very curious to see what this kind of script looks like, if you are amenable to sharing.
Its good to learn many different stuffs and giving us every details on the digital files.